sticker: emoji//1f40d🐍
🐍
3주차 활동 내용
3주차 목표
- 음성 패턴 인식 라이브러리 공부하기
활동결과
-
Speech Recognition
- SpeechRecognition은 한국어를 포함해 영어, 프랑스어, 중국어 등 다양한 언어의 음성 인식 관련 라이브러리로, 내부적으로 구글, 마이크로소프트, ibm등 빅테크 기업들의 우수한 알고리즘이 사용된 api를 이를 통해 쉽게 사용할 수 있다.

위와 같이 설치하고 난 뒤, 사용 예시는 아래와 같다.

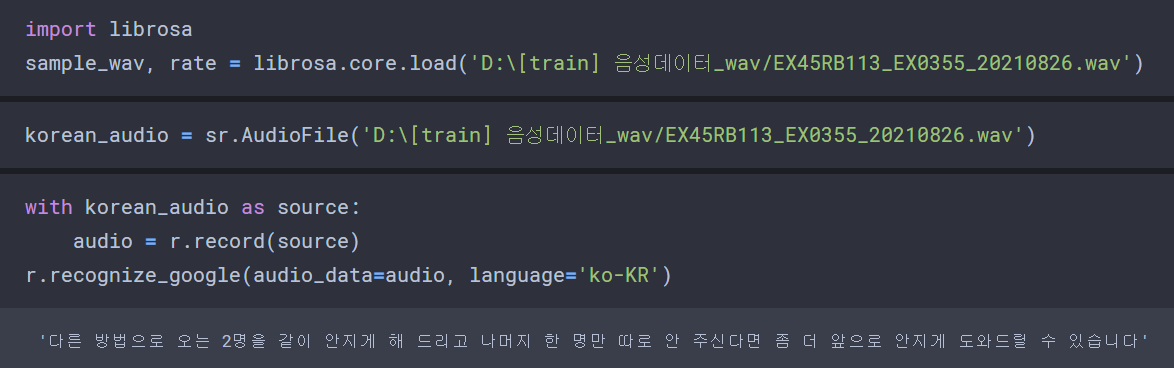
Google Web Speech API의 경우 위처럼 audio 파일과 언어를 변수로 지정하면 음성의 텍스트 변환이 가능하다.
- SpeechRecognition은 한국어를 포함해 영어, 프랑스어, 중국어 등 다양한 언어의 음성 인식 관련 라이브러리로, 내부적으로 구글, 마이크로소프트, ibm등 빅테크 기업들의 우수한 알고리즘이 사용된 api를 이를 통해 쉽게 사용할 수 있다.
-
Librosa
- Librosa 라이브러리는 음성 데이터를 다루는 대표적인 라이브러리이다. 간단하게 wav파일을 불러와서 파형을 직접 가공할 수도 있고, FFT나 MFCC 등 다양한 형태로 변환하는 기능들도 제공한다.
- waveform(파형)

- FFT(Fast Fourier Transform)
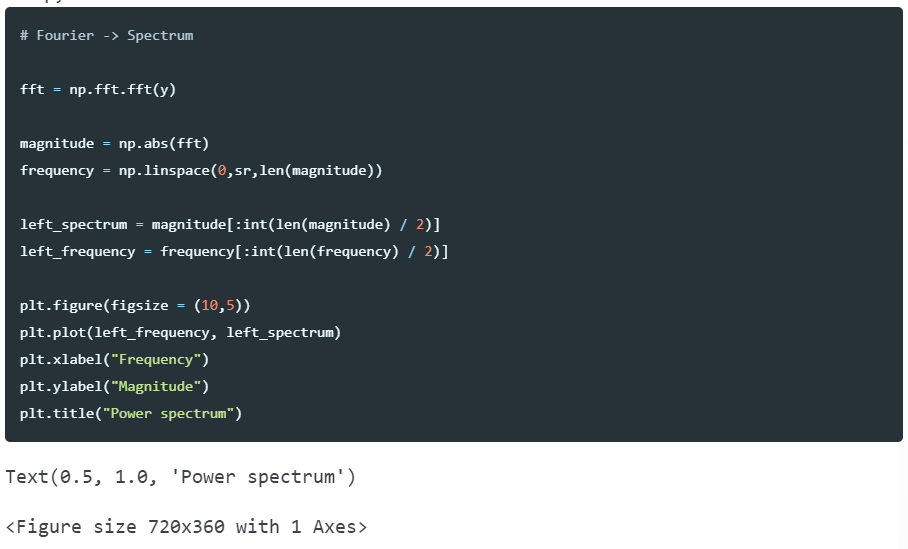
- STFT(Short - Time Fourier Transform)
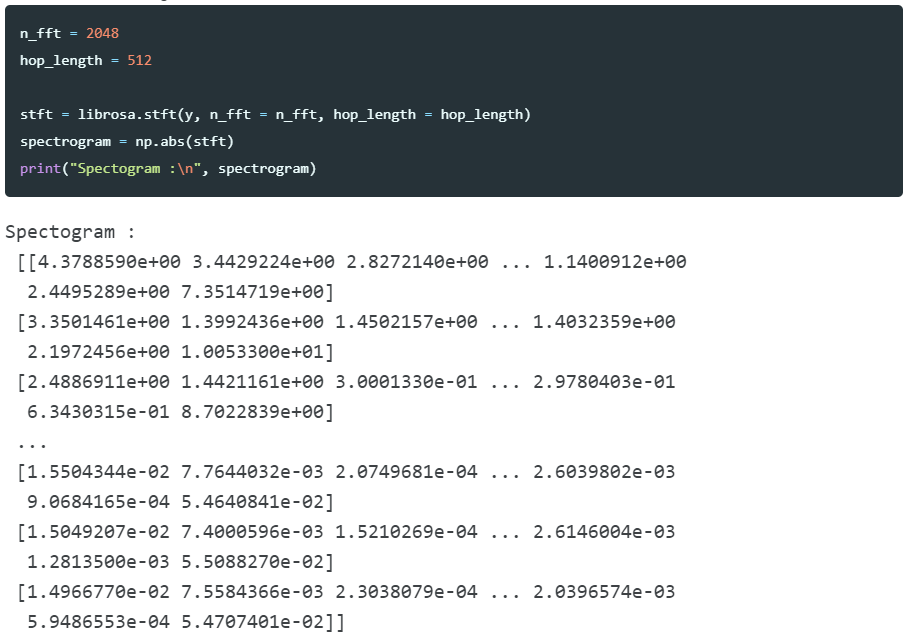
-
STT
- STT는 배치 음성 인식과 스트리밍 음성 인식으로 나뉜다.
- 배치 음성 인식
- 통상적으로 STT 음성 인식을 말할 때는 배치 음성 인식을 뜻한다.
- 긴 길이의 음성의 음성을 한 번에 입력으로 받아 전체 음성에 대해서 한 번에 받아쓰기를 하는 방식다.
- 입력으로 받는 음성의 길이에 따라 받아쓰기 속도가 다를 수 있다.
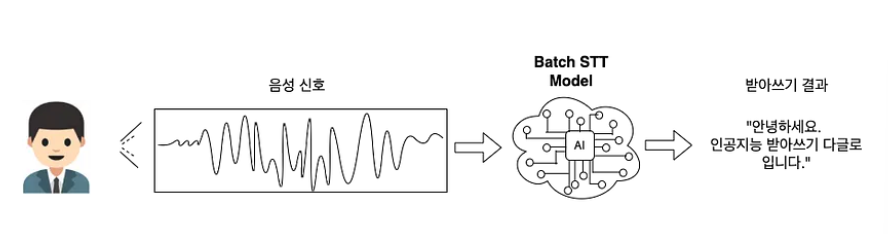
- 배치 단위 음성 인식의 Encoder는 아래 그림처럼 전체 음성을 입력으로 받아서 특징을 추출하고, Decoder는 추출된 특징을 기반으로 음성 인식을 수행한다.
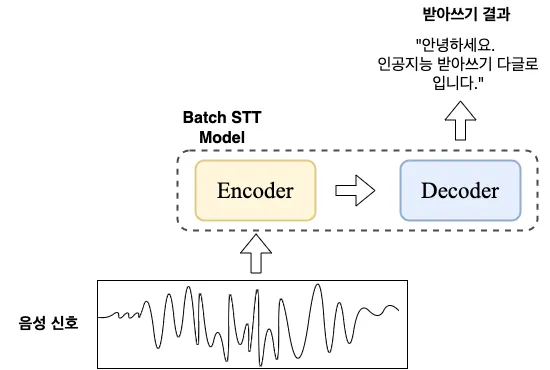
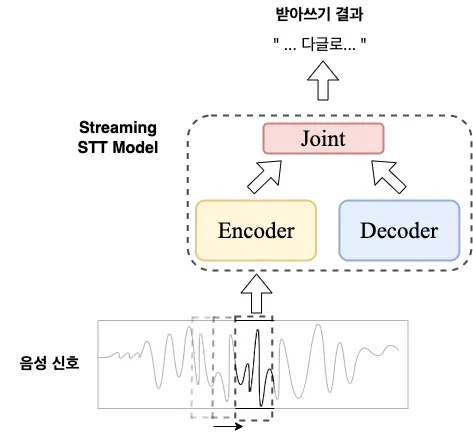
- 스트리밍 음성 인식
- 스트리밍 음성 인식은 이름에서 알 수 있듯이 스트리밍 형태로 입력되는 형태로 입력되는 음성을 실시간으로 빠르게 받아쓰는 방식이다.
- 전체 음성의 길이와 상관없이 일정한 속도로 입력 받는 음성을 받아쓸 수 있다.

- 스트리밍 음성 인식의 Encoder는 일정한 길이의 단위의 짧은 음성을 받아 짧은 특징을 추출하고, Decoder는 앞서 출력한 글자에서 문맥의 정보를 추출한다. Joint Nerwork는 앞서 추출된 음성 정보와 문맥 정보를 활용해서 최종적으로 다음에 올 글자를 예측한다.
Interactive Graph
Table Of Contents